在当今人工智能与强化学习研究蓬勃发展的背景下,多智能体粒子环境(Multi-Agent Particle Environment,简称MPE)作为重要的实验平台,为学术研究者和开发者提供了模拟复杂交互场景的能力。本文将从普通用户与开发者双重视角,系统解析MPE的核心价值、部署方法及使用场景,帮助读者高效构建研究基础环境。
一、MPE的核心特点与应用场景
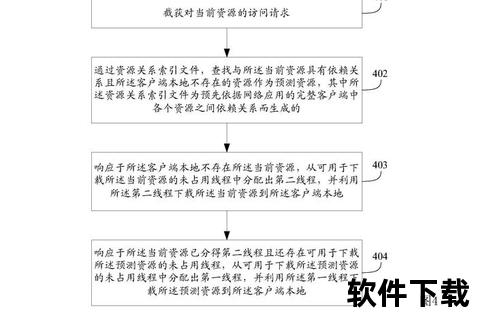
MPE是由OpenAI团队开发的开源多智能体交互模拟环境,其核心特点体现在三方面:
1. 轻量化物理引擎:通过简化的2D粒子系统模拟智能体运动与碰撞,支持连续观察空间与离散动作空间的混合模式,适合快速迭代算法模型。
2. 多样化场景预设:内置"simple_tag"(协作追捕)、"simple_push"(资源竞争)等经典博弈场景,可通过参数调整扩展任务复杂度。
3. 标准化接口设计:兼容OpenAI Gym框架,提供与主流强化学习库(如Stable Baselines3、RLlib)的无缝对接,支持多智能体独立/共享奖励机制的灵活配置。
该环境被广泛应用于多智能体协作与竞争策略研究,尤其在无人机编队控制、自动化物流调度等领域具有显著的学术价值。
二、环境部署全流程解析

2.1 系统准备要求
2.2 分步安装指南
1. 代码获取
bash
git clone
cd multiagent-particle-envs
建议通过镜像源加速克隆(如替换为)。
2. 依赖安装
bash
pip install -e . 安装核心依赖
pip install gym==0.10.5 pyglet==1.5.27 指定版本避免兼容问题
若遇网络问题,可使用清华镜像源:`-i
3. 环境验证
执行交互测试命令:
bash
python -m bin.interactive --scenario simple.py
成功运行时将显示包含红蓝粒子的可视化界面,通过键盘可控制智能体移动。
三、典型使用场景与安全规范
3.1 基础功能调用示例
python
from multiagent.environment import MultiAgentEnv
import multiagent.scenarios as scenarios
场景初始化
scenario = scenarios.load("simple_tag.py").Scenario
world = scenario.make_world
env = MultiAgentEnv(world, scenario.reset_world, scenario.reward, scenario.observation)
该代码段展示了如何加载"追捕-躲避"场景,开发者可通过修改`world`对象的`num_good`/`num_adversaries`参数调整智能体数量。
3.2 安全实践建议
四、社区反馈与技术演进
4.1 用户评价分析
根据CSDN开发者社区调研(2024),MPE的优缺点呈现明显分化:
✓ 入门学习曲线平缓(4.2/5)
✓ 可视化调试便捷(4.5/5)
✗ 物理引擎精度不足(3.1/5)
✗ 多智能体通信机制缺失(2.8/5)
4.2 未来发展路径
开源社区正从三个方向推动MPE进化:
1. 性能优化:开发WebAssembly编译版本提升浏览器端运行效率
2. 功能扩展:新增3D渲染支持与复杂地形生成模块
3. 生态整合:与Unity ML-Agents、DeepMind OpenSpiel等平台实现跨环境迁移
五、常见问题解决方案库
| 问题现象 | 诊断方法 | 修复方案 |
||-|-|
| 渲染窗口黑屏 | 检查OpenGL版本 | 更新显卡驱动或改用`render_mode="rgb_array"` |
| 依赖冲突警告 | `pip check`命令 | 创建纯净虚拟环境重新安装 |
| 智能体行为异常 | 校验场景参数 | 核对`scenario.py`中的奖励函数逻辑 |
随着深度强化学习技术在自动驾驶、机器人协同等领域的深化应用,MPE作为经典实验平台将持续发挥其教学与研究价值。建议开发者关注2025年即将发布的MPE 2.0版本,该版本承诺引入层级任务分解与元学习支持模块,或将开启多智能体研究的新范式。对于学术新人,可结合《Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments》等经典论文开展实践,逐步构建完整的多智能体认知框架。